
How to create an AI chat chain with LangChain, Pinecone, and memory
In recent times, the evolution of AI has been permeating various sectors of businesses and the day-to-day lives of individuals. The applicability of artificial intelligence can be immensely useful in many aspects of programming, such as generating reports, deriving insights, automating processes, processing data, and most notably, in creating chatbots trained with specific data to behave in unique ways and provide contextually relevant responses.
With this development, new terminology has become popular for those working with AI, including embeddings, vectors, contexts, LangChain, and more. In this article, we'll discuss how to create a chatbot using LangChain, Pinecone, and Upstash, with Next.js. The goal is to have an AI system ready to answer any question about an external context, store the history of message exchanges between the user and AI in a database, and use an intelligent search system to find the most appropriate response.
In this article, we'll build our chatbot using Next.js, utilizing LangChain to manage conversation chains, Pinecone to handle a vector database for executing semantic similarity searches, and Upstash to store the history of message exchanges between the user and the AI.
Before we start
As we're about to create a project that leverages a vector database for embeddings and injects context into the AI to enable it to answer questions, it's important that you have an account with Pinecone.
You'll need to follow the steps laid out by Pinecone to create and populate a vector index, as we'll be consuming it in this project. For this, you can follow the steps outlined in the Quickstart.
In a real-world application, you'll need to devise a strategy for performing upsert operations on the vectors in your Pinecone index in accordance with your application's context. In this article, however, we'll focus more on how to consume the vector index for performing semantic similarity searches and passing context to the AI.
Creating a Next.js project
To kick things off, let's create a Next.js project using the npx create-next-app command. We'll name our project demo-ai-chat:
npx create-next-app@latest
Installing the dependencies
Now, let's install the dependencies that we'll be using in this project. We'll install the following:
langchain: a library for managing conversation chains@pinecone-database/pinecone: a library for dealing with a vector database and executing semantic similarity searches@upstash/redis: a library for managing the Redis databaseai: an interoperable, streaming-enabled, edge-ready software development kit for AI apps built with React and Svelte by Vercel
pnpm install langchain @pinecone-database/pinecone @upstash/redis ai
Defining a simple interface for the chat
To start, let's define a simple interface for the chat using the helper functions from the ai library provided by Vercel. Let's modify the app/page.tsx file with the following content:
'use client'
import { useChat } from 'ai/react'
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat()
return (
<div className="stretch mx-auto flex w-full max-w-md flex-col py-24">
{messages.length > 0
? messages.map((m) => (
<div key={m.id} className="whitespace-pre-wrap">
{m.role === 'user' ? 'User: ' : 'AI: '}
{m.content}
</div>
))
: null}
<form onSubmit={handleSubmit}>
<input
className="fixed bottom-0 mb-8 w-full max-w-md rounded border border-gray-300 p-2 shadow-xl"
value={input}
placeholder="Say something..."
onChange={handleInputChange}
/>
</form>
</div>
)
}
Creating the API to interact with AI
First, let's create a function to instantiate our Pinecone database
To start, let's create a function to instantiate our Pinecone database. For this, let's create a file named lib/pinecone.ts with the following content:
import { PineconeClient } from '@pinecone-database/pinecone'
export const pinecone = new PineconeClient()
export const initPinecone = async () => {
if (!process.env.PINECONE_API_KEY || !process.env.PINECONE_ENVIRONMENT) {
throw new Error(
'PINECONE_API_KEY and PINECONE_ENVIRONMENT environment variables must be set'
)
}
await pinecone.init({
apiKey: process.env.PINECONE_API_KEY,
environment: process.env.PINECONE_ENVIRONMENT,
})
}
We'll use this function to connect our application to Pinecone and perform semantic searches with LangChain. For now, let's set it aside and create a function to instantiate our Upstash database.
Creating a function to instantiate our Upstash database
Now that we've managed to connect our application to Pinecone, let's create a function to instantiate our Upstash database. For this, let's create a file named lib/upstash.ts with the following content:
import { Redis } from '@upstash/redis'
let cachedDb: Redis
export async function getRedisClient() {
if (cachedDb) {
return cachedDb
}
if (!process.env.UPSTASH_ENDPOINT || !process.env.UPSTASH_TOKEN) {
throw new Error(
'Please define the UPSTASH_ENDPOINT and UPSTASH_TOKEN environment variables inside .env.local'
)
}
const client = new Redis({
url: process.env.UPSTASH_ENDPOINT,
token: process.env.UPSTASH_TOKEN,
})
cachedDb = client
return client
}
With this function, we can now connect our application to Upstash and save the history of message exchanges between the user and AI. For now, let's set it aside and focus on implementing LangChain, connecting to Pinecone, and saving the history of message exchanges between the user and AI in Upstash, all through a single chain. Sounds powerful, right? Let's get down to the heavy lifting.
Creating an API to interact with the AI
Now that we've managed to connect our application to both Pinecone and Upstash, let's create an API to interact with the AI. For this, let's create a file named app/api/chat/route.ts with the following content:
import { StreamingTextResponse, LangChainStream } from 'ai'
import { ChatOpenAI } from 'langchain/chat_models/openai'
import { PineconeStore } from 'langchain/vectorstores/pinecone'
import { OpenAIEmbeddings } from 'langchain/embeddings/openai'
import { ConversationalRetrievalQAChain } from 'langchain/chains'
import { BufferMemory } from 'langchain/memory'
import { initPinecone, pinecone } from '@/lib/pinecone'
export const runtime = 'edge'
export async function POST(req: Request) {
const { messages } = await req.json()
const { stream, handlers } = LangChainStream()
await initPinecone()
const pineconeIndex = pinecone.Index('my-index')
const vectorStore = await PineconeStore.fromExistingIndex(
new OpenAIEmbeddings(),
{
pineconeIndex,
namespace: 'my-namespace',
textKey: 'content',
}
)
const mainLLM = new ChatOpenAI({
streaming: true,
modelName: 'gpt-4',
callbacks: [handlers],
})
const underlyingLLM = new ChatOpenAI({
modelName: 'gpt-4',
})
const chain = ConversationalRetrievalQAChain.fromLLM(
mainLLM,
vectorStore.asRetriever(),
{
memory: new BufferMemory({
memoryKey: 'chat_history',
inputKey: 'question',
outputKey: 'text',
returnMessages: true,
}),
questionGeneratorChainOptions: {
llm: underlyingLLM,
},
}
)
chain
.call({
question: messages[messages.length - 1].content,
})
.catch(console.error)
return new StreamingTextResponse(stream)
}
Here we need to pay attention to some important points:
Using the correct namespace
In the above code, you'll need to replace YOUR_NAMESPACE_HERE with the namespace of your Pinecone index. You can find your Pinecone index's namespace on the index page within Pinecone.
Using the correct value for textKey
In the above code, you'll need to replace the content value with the value of the field you used to save the text of your document in your Pinecone index. When performing the vector upsert in Pinecone, you can define some metadata. It's important to save the content of each vector in the metadata so you can perform a semantic search using the created vectors and retrieve the document content. This key will be used internally by LangChain, accessing the vector metadata to retrieve the document content.
Using the right model
Depending on the purpose of your AI chatbot, you may need the AI to perform more complex tasks, so you might choose to use a more powerful model like gpt-4 or a faster and simpler model like gpt-3.5-turbo. In this example, we'll proceed with gpt-4 and end up using both later on.
Unoptimized result
Vamos ver o que temos construído até então:
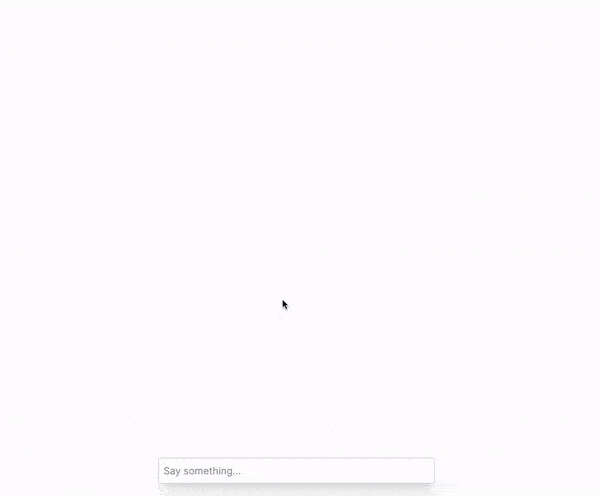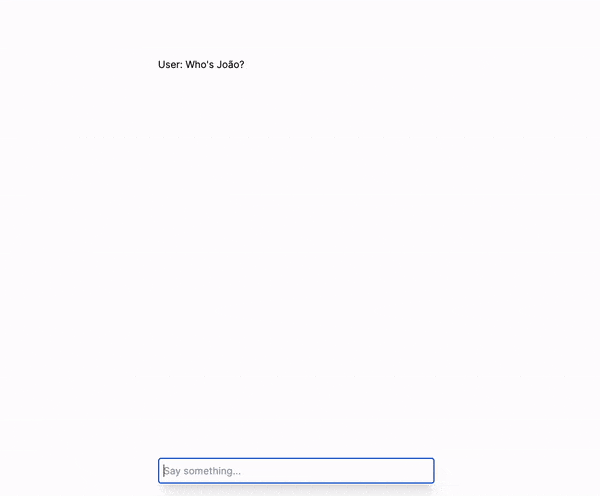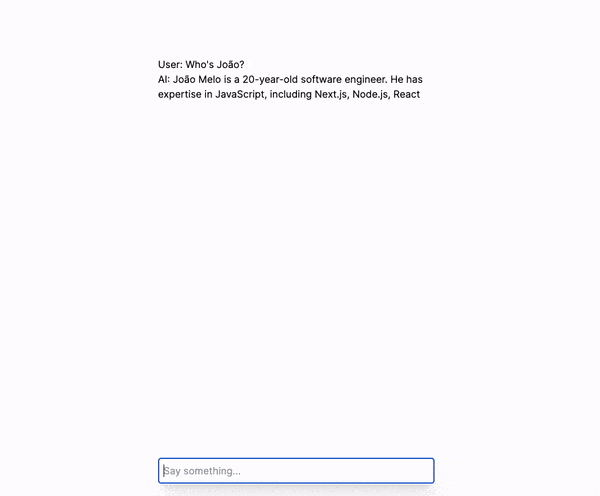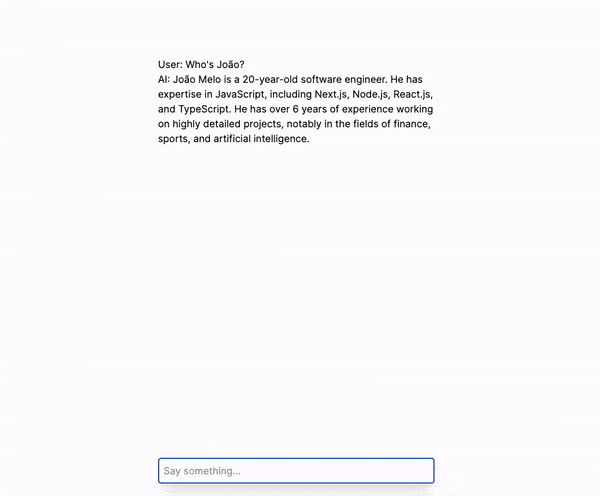
With what we have built so far, we have a chat with an AI that has interesting capabilities, such as responding to questions about a context that is indexed in the Pinecone vector database. Let's review what we have so far step by step.
- First, our implementation connects to our Pinecone database.
- We instantiate an AI model using the OpenAI model,
gpt-4. - We create a chain with LangChain, specifying the steps that the LangChain should follow:
- Store all messages exchanged by the user and the AI in memory.
- Perform a semantic search in the Pinecone vector database to find the vectors that have the highest similarity with the user's question.
- Ask the AI to refactor the user's question based on the memory history.
- With the refactored response, use the context found in Pinecone to answer the user's question.
- Return the response through text streaming.
One thing that may confuse you is the third step of the chain we created. What exactly does it mean for the LangChain to refactor the user's question? Let's understand this better.
Refactoring the user's question
Imagine we have the following sequence of messages exchanged between the user and the AI:
User: Who is Guillermo Rauch?
AI: Guillermo Rauch is an Argentine programmer and the CEO of Vercel.
User: Where does he live?
AI: He lives in San Francisco.
Notice how the AI answered the user's question based on the context it has about Guillermo Rauch. Now, imagine having only the following question in the history:
User: Where does he work?
The AI would not know that the pronoun he refers to Guillermo Rauch and therefore couldn't provide information about him.
That's why the LangChain refactors the user's question based on the memory history. This way, the AI can understand the context of the question and respond accordingly. With this intelligence, the AI can refactor the final user's question to something like:
User: Where does Guillermo Rauch work?
Here's a real example of how the AI refactors the user's question:

My original question was "How old is he?," but the AI refactored it to "How old is João?" so that the context search in Pinecone would be more effective.
Now that we understand how the LangChain uses the AI to refactor the question, it is easier to understand why we need to create two AI models. One is used to generate the final answer, while the other is used for the step of refactoring the user's question. Since we want only the final answer to be returned through streaming, we provide the streaming: true configuration only to the mainLLM, which is the model that will generate the final answer.
Remember that the step of refactoring the user's question occurs only when there is some history of messages exchanged between the user and the AI. If there is no history, the AI will not refactor the user's question. This means that for the first question asked to the AI, this step won't occur because there is no history. However, starting from the second question, this step will happen since there is already history.
Returning to our chat
With the current version of our chat, we have something that can provide some value but will encounter some problems. Let's see what these problems are and how we can solve them.
Problem 1: Chat history is lost with every new request
Since we are using only BufferMemory in our chain, it means that we keep the message history only in memory. This implies that with every new request, the message history is lost. This becomes a problem because we cannot leverage the context of the message history to refactor the user's question.
One solution could be to use the messages variable we receive in the request to build the message history. However, that is not a good idea because the messages variable is just an array of messages stored in the user's browser. This means that the user can easily manipulate the message history or completely lose the message history by closing the chat page. Yes, we can solve this by using some form of disk storage on the user's machine, such as localStorage, but it is still not the ideal scenario because the message history of that user would be available only in that browser and computer, not across all devices the user uses.
"But João, what if I store the message history in a database?" - You.
Yes, that's a good idea. Let's see how we can solve the first problem of our chain.
Introducing UpstashRedisChatMessageHistory
LangChain provides us with a memory implementation that stores the message history in external databases. I recommend you take a look at the options they offer. In this article, we will use UpstashRedisChatMessageHistory, which stores the message history in Upstash, a Redis database that is extremely performant and has low latency.
All we need to do is:
- Import
UpstashRedisChatMessageHistoryfromlangchain. - Import the function we created at the beginning of this article to connect to Upstash.
- Create an instance of
UpstashRedisChatMessageHistory. - Pass the
UpstashRedisChatMessageHistoryinstance to theBufferMemoryin our chain.
And that's it! Here's how our code looks:
// ...your other imports
import { UpstashRedisChatMessageHistory } from 'langchain/stores/message/upstash_redis'
import { getRedisClient } from '@/lib/upstash'
// ...your code
const chatHistory = new UpstashRedisChatMessageHistory({
sessionId: 'chat-session-1', // you can use the user id here, for example
client: await getRedisClient(),
})
const chain = ConversationalRetrievalQAChain.fromLLM(
mainLLM,
vectorStore.asRetriever(),
{
memory: new BufferMemory({
memoryKey: 'chat_history',
inputKey: 'question',
outputKey: 'text',
returnMessages: true,
chatHistory,
}),
questionGeneratorChainOptions: {
llm: underlyingLLM,
},
}
)
// ...your code
Now, we can see that the message history is stored in Upstash, not in memory. This means that the message history is not lost with every new request, and we can leverage the context of the message history to refactor the user's question.

Problem 2: High costs and low performance
Now that we have solved the first problem, let's look at the second problem we face with our chain. Let's see what happens when we ask a question to the AI:

The delay before starting to write a response is due to two main factors:
- Semantic search in Pinecone
- Refactoring step of the user's question
In the semantic search, there isn't much we can do. But in the refactoring step of the user's question, we can make a small change to make the process faster.
Let's change the model we are using in underlyingLLM to gpt-3.5-turbo. This model is faster and simpler, and it will help us refactor the user's question more quickly.
// ...your code
const underlyingLLM = new ChatOpenAI({
modelName: 'gpt-3.5-turbo',
})
// ...your code
Since this step does not require such a powerful model because it involves simple reasoning, we can use a simpler and faster model, and thus speed up the process.
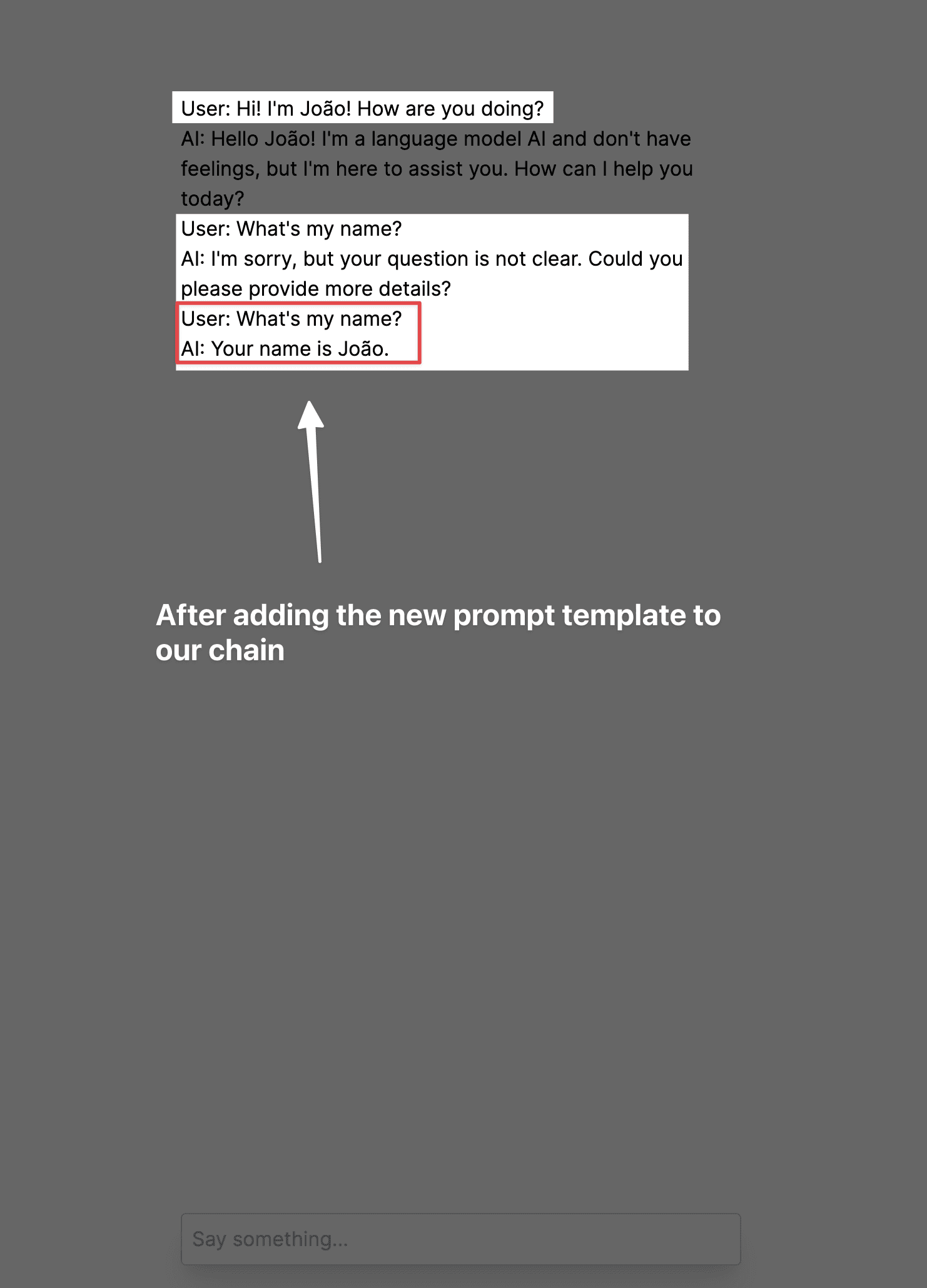
Problem 3: Relevant context from the message history is not properly utilized
Take a look at what happens when we ask the AI a question about something mentioned in the message history:

This happens because in the step of refactoring the user's question, LangChain provides instructions only to refactor the question and make it clearer and more concise. This means that if the person is mentioning any information that was said in the message history, that information is not effectively utilized to refactor the user's question.
To address this, we can make a small adjustment to the AI instruction in this step to consider the relevant portion of the message history according to the user's question, if there is any relevant portion.
To make this adjustment, we create a new constant with a prompt that has clearer and stronger instructions, which will prompt the AI to use relevant excerpts from the message history that may be useful in answering the question. This way, the AI will not solely depend on the context obtained from Pinecone but also consider any important excerpts from the message history. Here's how our code looks like:
// ...your code
const QA_UNDERLYING_PROMPT_TEMPLATE = `Given the following conversation and a follow up question, return the conversation history excerpt that includes any relevant context to the question if it exists and rephrase the follow up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Your answer should follow the following format:
\`\`\`
Use the following pieces of conversation context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
Relevant chat history excerpt:
<Relevant chat history excerpt as context here or "N/A" if nothing found>
Question: <Rephrased question here>
\`\`\`
Your answer:
`
// ...your code
const chain = ConversationalRetrievalQAChain.fromLLM(
mainLLM,
vectorStore.asRetriever(),
{
memory: new BufferMemory({
memoryKey: 'chat_history',
inputKey: 'question',
outputKey: 'text',
returnMessages: true,
chatHistory,
}),
questionGeneratorChainOptions: {
llm: underlyingLLM,
template: QA_UNDERLYING_PROMPT_TEMPLATE,
},
}
)
// ...your code
With this change, we are telling the AI that if there is any relevant excerpt in the message history, it should be used to answer the user's question. Here's the result:
Problem 4: Exceeding LLM token limit
As your users continue to use your chat, the memory of each chat session becomes increasingly larger. This means that with each new request, the LangChain will include the message history in the context of the AI, which can cause you to exceed the AI's token limits. To address this scenario, we have a few options:
- Limit the size of the message history, so that your users have a clean message history after a certain number of exchanged messages.
- Instead of using
BufferMemory, you can use other memory implementations provided by LangChain to, for example, keep only the most recentNmessages or always summarize the message history.
If you want to offer a good user experience, I recommend exploring the memory options that LangChain provides. The tool offers ways to optimize this.
Optimized result
Now that we have addressed all the problems encountered with our chain, we have a well-functioning chat system that can provide significant value to our users. Our AI has the main optimizations we need to deliver a good user experience, with valid and contextualized responses, access to previous conversation memory, and good performance.
Here's the final code of our chat:
import { StreamingTextResponse, LangChainStream } from 'ai'
import { ChatOpenAI } from 'langchain/chat_models/openai'
import { PineconeStore } from 'langchain/vectorstores/pinecone'
import { OpenAIEmbeddings } from 'langchain/embeddings/openai'
import { UpstashRedisChatMessageHistory } from 'langchain/stores/message/upstash_redis'
import { ConversationalRetrievalQAChain } from 'langchain/chains'
import { initPinecone, pinecone } from '@/lib/pinecone'
import { getRedisClient } from '@/lib/upstash'
import { BufferMemory } from 'langchain/memory'
export const runtime = 'edge'
const QA_UNDERLYING_PROMPT_TEMPLATE = `Given the following conversation and a follow up question, return the conversation history excerpt that includes any relevant context to the question if it exists and rephrase the follow up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Your answer should follow the following format:
\`\`\`
Use the following pieces of conversation context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
Relevant chat history excerpt:
<Relevant chat history excerpt as context here or "N/A" if nothing found>
Question: <Rephrased question here>
\`\`\`
Your answer:
`
export async function POST(req: Request) {
const { messages } = await req.json()
const { stream, handlers } = LangChainStream()
await initPinecone()
const pineconeIndex = pinecone.Index('my-index')
const vectorStore = await PineconeStore.fromExistingIndex(
new OpenAIEmbeddings(),
{
pineconeIndex,
namespace: 'demo-ai-chat',
textKey: 'content',
}
)
const slowerModel = new ChatOpenAI({
streaming: true,
modelName: 'gpt-4',
callbacks: [handlers],
})
const fasterModel = new ChatOpenAI({
streaming: false,
modelName: 'gpt-3.5-turbo',
})
const chatHistory = new UpstashRedisChatMessageHistory({
sessionId: 'chat-session-1',
client: await getRedisClient(),
})
const chain = ConversationalRetrievalQAChain.fromLLM(
slowerModel,
vectorStore.asRetriever(),
{
memory: new BufferMemory({
memoryKey: 'chat_history',
inputKey: 'question',
outputKey: 'text',
returnMessages: true,
chatHistory,
}),
questionGeneratorChainOptions: {
llm: fasterModel,
template: QA_UNDERLYING_PROMPT_TEMPLATE,
},
}
)
chain
.call({
question: messages[messages.length - 1].content,
})
.catch(console.error)
return new StreamingTextResponse(stream)
}
GitHub repository
If you want to see the code in action, you can access the GitHub repository of this project.
Conclusion
In this article, we've learned how to create a chatbot using LangChain, Pinecone, and Upstash, with Next.js and streaming. We've learned how to create a chain with LangChain, connect to Pinecone, and save the history of message exchanges between the user and AI in Upstash, all through a single chain. We've also learned how to use the UpstashRedisChatMessageHistory to save the history of message exchanges between the user and AI in Upstash, and how to use the gpt-3.5-turbo model to speed up the process of refactoring the user's question. Also, we've walked through how to optimized the chain to take advantage of the relevant context of the history of message exchanges between the user and AI.
I still have a great optimization I'd like to share with you, but I'll leave that for the next post. This optimization makes context injection into AI brought from Pinecone more effective and we just use the amount of context needed without consuming more tokens than necessary to answer the user's query. It will be a very interesting article, so stay tuned for it!
I hope you enjoyed this article and that it helps you create your own AI chatbot. If you have any questions, feel free to reach out to me on Twitter at @joaomelo.